DCARL: A Divide-and-Conquer Framework for Autoregressive Long-Trajectory Video Generation
DCARL: A Divide-and-Conquer Framework for Autoregressive Long-Trajectory Video Generation
분할정복(Divide-and-Conquer) 프레임워크로 자기회귀 장궤적 비디오 생성의 구조적 안정성과 고품질을 동시 달성. 32초 비디오에서 FID 19.2, FVD 203.7로 SOTA(SEVA 22.2/548.0) 대비 압도적 우위. 카메라 궤적 준수도(ATE 0.237)에서도 최고 성능.
연구 배경 및 동기
장시간 비디오 생성(Long Video Generation)은 현재 비디오 AI에서 가장 도전적인 문제 중 하나이다. 기존 자기회귀(Autoregressive) 방식은 이전 프레임을 조건으로 다음 프레임을 생성하는데, 시간이 길어질수록 **시각적 드리프트(visual drift)**가 누적된다. 색감이 서서히 변하고, 구조가 왜곡되며, 카메라 궤적이 의도와 달라지는 현상이다.
이 문제에 대한 접근법은 크게 두 가지가 있다:
- 순수 자기회귀(Pure AR): 이전 프레임만을 조건으로 순차 생성. 지역적 연속성은 좋지만 장기 일관성이 저하.
- 분할정복(Divide-and-Conquer): 먼저 희소한 키프레임을 생성하고, 그 사이를 보간. 전역 일관성은 좋지만 키프레임 간 전환이 부자연스러울 수 있음.
DCARL은 이 두 접근의 장점을 결합한다. 분할정복의 구조적 안정성과 자기회귀의 고품질 밀집 생성을 동시에 달성하는 프레임워크이다.

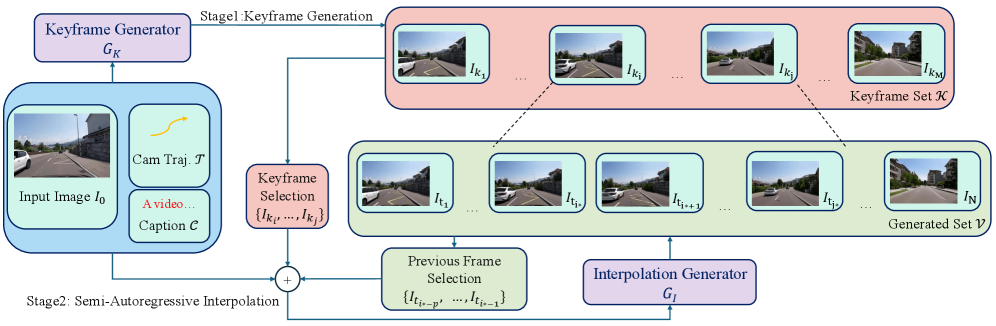
방법론: 2단계 분할정복 파이프라인
아키텍처 개요
DCARL은 두 개의 독립적인 생성기로 구성된다. 각각은 Wan2.1-T2V-1.3B 아키텍처를 기반으로 한 DiT(Diffusion Transformer) 기반 플로우 매칭(flow matching) 모델이다.
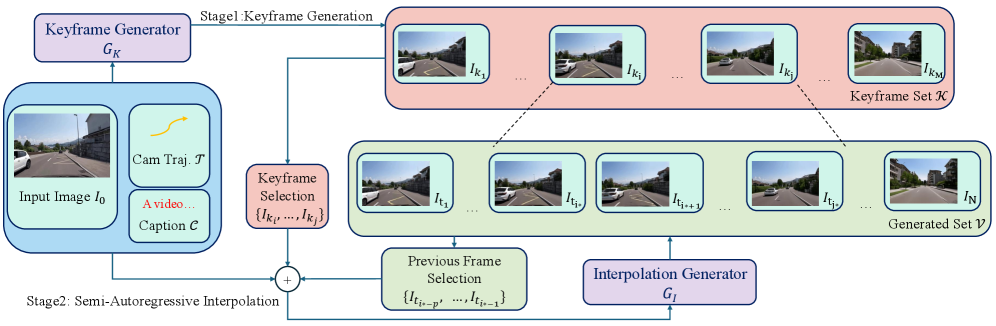
Stage 1: Keyframe Generator (키프레임 생성기)
키프레임 생성기의 핵심 설계 원칙은 **"공간-구조 보존(Spatial-Structural Preservation)"**이다. 기존 비디오 생성 모델들은 시간 축을 VAE로 압축(temporal compression)하여 연산 효율을 높이지만, 이 과정에서 프레임 간 정보가 혼합되어 구조적 디테일이 손실된다. DCARL의 키프레임 생성기는 이 시간 압축을 의도적으로 제거한다.
구체적 구현: 키프레임들을 시퀀스가 아닌 배치(batch-wise) 독립 이미지로 처리한다. 각 키프레임은 개별적으로 VAE 인코딩되며, 시간축 압축에 의한 정보 손실이 원천적으로 발생하지 않는다. 대신, 키프레임 간의 시간적 관계는 DiT의 attention 메커니즘을 통해 학습한다.
학습 시 키프레임 간격(temporal stride) $\Delta_k$는 {4, 8, 16}에서 랜덤 샘플링하여 다양한 시간 해상도에 대한 일반화를 확보하고, 추론 시에는 $\Delta_k = 8$을 고정 사용한다. 학습 데이터에서 키프레임 수는 $|K| = 21$로 설정된다.
Stage 2: Interpolation Generator (보간 생성기)
보간 생성기는 키프레임 사이의 밀집 프레임(dense frames)을 자기회귀적으로 합성한다. 이 과정에서 두 가지 핵심 기술이 적용된다:
1) Motion-Inductive Noisy Conditioning (움직임 유도 노이즈 컨디셔닝)
키프레임을 보간 조건으로 사용할 때, 깨끗한(clean) 키프레임을 그대로 제공하면 모델이 **복사 지름길(copy shortcut)**을 학습한다. 즉, 키프레임을 그대로 복사하고 사이 프레임을 대충 채우는 패턴이 발생한다. DCARL은 이를 방지하기 위해 키프레임 잠재 벡터에 의도적으로 노이즈를 추가한다:
- 혼합 계수: $\alpha_c = 0.7$, $\sigma_c = 0.3$
- 학습과 추론 모두에서 동일한 노이즈 수준 적용
이 설계는 모델이 키프레임의 구조적 정보(카메라 위치, 장면 레이아웃)만 활용하고, 픽셀 레벨의 디테일은 자체 생성하도록 유도한다.
2) Seamless Boundary Consistency (이음새 없는 경계 일관성)
자기회귀 보간 시 이전 세그먼트와의 경계에서 불연속이 발생할 수 있다. DCARL은 잠재 벡터 치환(latent substitution) 방식으로 이를 해결한다:
- 이전 세그먼트의 마지막 $p = 1$ 프레임의 노이즈-프리 잠재 벡터를 현재 세그먼트의 시작 부분에 직접 대입
- 이 프레임이 "앵커" 역할을 하여 시간적 연속성 보장
정량적 결과
ODV-YouTube 데이터셋 (32초 비디오)
| 방법 | FID↓ | FVD↓ | ATE↓ | ARE↓ |
|---|---|---|---|---|
| DiffF | 35.0 | 664.1 | 0.469 | 19.448 |
| SelfF | 58.0 | 2113.6 | 0.610 | 14.386 |
| DeepF | 42.3 | 1558.5 | 0.571 | 15.144 |
| Vista | 66.7 | 1550.0 | 0.641 | 19.332 |
| SEVA | 22.2 | 548.0 | 0.294 | 8.527 |
| DCARL | 19.2 | 203.7 | 0.237 | 7.669 |
DCARL은 FID에서 차선 방법(SEVA) 대비 13.5% 개선(22.2 → 19.2), FVD에서 62.8% 개선(548.0 → 203.7)을 달성했다. 특히 FVD의 극적인 개선은 시간적 일관성이 크게 향상되었음을 의미한다.
시간 구간별 성능 분석 (ODV-YouTube, 32초)
| 방법 | 0-8초 FID/FVD | 8-16초 FID/FVD | 16-24초 FID/FVD | 24-32초 FID/FVD |
|---|---|---|---|---|
| DiffF | 25.3/390.7 | 39.8/684.5 | 45.2/856.8 | 54.1/1067.1 |
| SEVA | 27.2/582.0 | 30.7/643.2 | 31.8/623.8 | 33.1/602.0 |
| DCARL | 19.6/191.4 | 25.1/255.8 | 27.3/276.0 | 28.6/313.8 |
이 시간 구간별 분석이 DCARL의 핵심 강점을 드러낸다. DiffF 같은 순수 AR 방법은 시간이 갈수록 FID가 25.3 → 54.1로 급격히 악화되지만, DCARL은 19.6 → 28.6으로 완만하게 증가한다. 이는 키프레임 앵커링이 장기 드리프트를 효과적으로 억제한다는 직접적 증거이다.
nuScenes 데이터셋 (16초, Zero-Shot Transfer)
| 방법 | FID↓ | FVD↓ | ATE↓ | ARE↓ |
|---|---|---|---|---|
| DiffF | 37.1 | 566.6 | 0.154 | 13.704 |
| SEVA | 35.9 | 487.9 | 0.117 | 6.289 |
| DCARL | 19.6 | 225.4 | 0.045 | 5.274 |
Zero-shot(학습에 사용하지 않은 데이터셋) 환경에서도 DCARL은 모든 메트릭에서 SOTA를 달성했다. 특히 ATE(카메라 궤적 오차)에서 0.045로, SEVA(0.117) 대비 61.5% 개선을 보여 카메라 제어 정밀도가 탁월하다.

Ablation Study: 키프레임의 필요성
| 설정 | FID↓ | FVD↓ | ATE↓ | ARE↓ |
|---|---|---|---|---|
| 키프레임 없음 (순수 AR) | 25.2 | 376.7 | 0.387 | 12.184 |
| DCARL Full | 19.2 | 203.7 | 0.237 | 7.669 |
키프레임을 제거하면 FVD가 203.7 → 376.7로 84.8% 악화되며, ATE도 0.237 → 0.387로 급증한다. 이는 키프레임이 장기 일관성 유지에 필수적임을 명확히 보여준다.
키프레임 설계 ablation (16초)
| 모델 | FID↓ | ATE↓ | ARE↓ |
|---|---|---|---|
| 시간 압축 사용 | 19.6 | 0.155 | 7.276 |
| DCARL (시간 압축 미사용) | 16.3 | 0.100 | 3.999 |
시간 압축을 사용하면 ARE가 7.276으로 약 2배 악화되어, 시간 압축 제거가 카메라 궤적 정밀도에 결정적 영향을 미침을 확인할 수 있다.

학습 상세
| 항목 | 값 |
|---|---|
| 베이스 모델 | Wan2.1-T2V-1.3B |
| 옵티마이저 | AdamW (LR: 5e-5, weight decay: 0.01, beta: 0.9/0.95) |
| 학습 스텝 | 30,000 (생성기당) |
| 배치 크기 | 16 (effective, 8x H100 GPU) |
| 데이터셋 | OpenDV-YouTube 480시간, 10fps, 1분 클립 |
| 카메라 포즈 | pi3로 0.5초 간격 재구성 |
| 키프레임 수 | $ |
한계점 및 향후 연구 방향
- 해상도 제한: 현재 구현은 중간 해상도에서 동작하며, 4K 이상의 고해상도 장비디오 생성에 대한 확장은 검증되지 않았다.
- 컨텐츠 다양성: 주로 주행 비디오(driving video)로 학습되어, 실내·항공·수중 등 다양한 도메인에서의 일반화는 추가 검증이 필요하다.
- 텍스트 제어: 카메라 궤적 기반 생성에 특화되어 있으며, 세밀한 텍스트 프롬프트 기반 내용 제어(예: "비 오는 날씨로 변경")는 지원하지 않는다.
- 추론 속도: 두 단계 생성이 순차적으로 수행되므로, 단일 모델 대비 추론 시간이 길어질 수 있다.

출처
| 플랫폼 | 링크 |
|---|---|
| ArXiv | 2603.24835 |
| ArXiv HTML | 전문 보기 |